Item Content and Transcription
Abbreviations and Expansions
Common abbreviations: the, that, ampersands
For common abbreviations like "yt" for
"that", "ye" for "the" that appear
often throughout the text, you do not need to use
choice or
expan; instead, you can simply tag
the abbreviation using the abbr tag
with a type value with the correct
word:
<abbr type="the">ye</abbr>
In most cases, ampersands do
not need to be tagged at all--they will be automatically
expanded in processing. However, do note that ampersands are
special characters in XML and cannot be represented simply by the
& character and must be typed in as
&
However, if the ampersand does not expand to "and",
then you must tag the abbreviation using the full
choice,
abbr, and
expan method below:
<choice><abbr>&c.</abbr><expan>et cetera</expan></choice>
| Abbreviation | Expanded Form | Encoding |
| Broyr | Brother |
<abbr type="Brother">Broyr</abbr> |
| anoyr | another |
<abbr type="another">anoyr</abbr> |
| fm | fm |
<abbr type="fm">fm</abbr> |
| qre | qre |
<abbr type="qre">qre</abbr> |
| yt | that |
<abbr type="that">yt</abbr> |
| ye | the |
<abbr type="the">ye</abbr> |
| ym | them |
<abbr type="them">ym</abbr> |
| yn | then |
<abbr type="then">yn</abbr> |
| yre | there |
<abbr type="there">yre</abbr> |
| ys | this |
<abbr type="this">ys</abbr> |
| qt | what |
<abbr type="what">qt</abbr> |
| qn | when |
<abbr type="when">qn</abbr> |
| qch | which |
<abbr type="which">qch</abbr> |
| qo | who |
<abbr type="who">qo</abbr> |
| qm | whom |
<abbr type="whom">qm</abbr> |
| wt | with |
<abbr type="with">wt</abbr> |
| yr | your |
<abbr type="your">yr</abbr> |
Uncommon abbreviations
Uncommon or unfamiliar abbreviations—like Revd—will often need
to be expanded in order to provide clarity and to facilitate
searching. To do so, first tag the abbreviation with the
abbr element, then tag your
expansion with an expan, and then
wrap both in a choice element. For
example:
<title>Letter from the <choice><abbr>Revd.</abbr><expan>Reverend</expan></choice> Mr. <persName>Lyon</persName></title>
Supplying, Regularizing, and Flagging Incorrect Text
Since the LiM represents multiple voices, we need to be explicit
in our signalling of our editorial interventions and judicious in
our appraisal of what kind of intervention we need to make.
There are three situations where editorial intervention is
necessary:
Text that must be supplied due to obscured page images, ink
blots, or other obfuscating factors
Non-normative spelling that we want to regularize for
searching purposes
Obvious errors
This list is in order of descending preference; in most cases, it
is too difficult to determine if something is truly an
"error" that can and should be corrected.
Supplying Text
Tag text that has been obscured in some way (usually lost in
the margin or the fold of the book) using the
supplied tag:
<lb/><supplied>I</supplied>rons upon him, which he looked upon
If you are not certain about the supplied text, then use the
cert attribute on
supplied with a value of
low:
provided that he
<lb/><supplied cert="low">w</supplied>ould not sit down, but come out as
Regularizing Text
Tag cases where a word differs from its normative form or
spelling and would benefit from regularization to help with
searching by tagging the original word using
orig, the regularized version using
reg, and wrapping both in a
choice element:
I had some share the effects of <choice><orig>wich</orig><reg>which</reg></choice>
Note that the names of people, places, organizations, and
objects should not be
regularized. Since all people, places, and organizations will be
tagged and associated with an person, place, or organization
entity, it is unnecessary to regularize these proper names.
Corrections
While we do not correct erroneous text, we do flag instances
where the word or phrase seems incorrect in some way by using the
sic tag:
<lb/>of Distinction, wait <sic>of</sic> General
Additions, Deletions, and Substitutions
Additions and deletions in text may appear in the text either in
isolation or as part of a single textual event.
Additions
In all cases, additions should be marked with the
add tag with its location encoded
using the place attribute. For
example:

In this case, text has been added above the line, which would
be encoded like so:
<lb/>Donell, <add place="above">George Moir the</add> Laird of Leckie,
Here, we can also tag the "George Moir the Laird of
Leckie" as a persName and
point to his xml:id:
<lb/>Donell, <persName ref="prs:MOIRG1"><add place="above">George Moir the</add> Laird of Leckie</persName>
Deletions
Tag text that has been marked for deleting using the
del element:
<title>Written in <del>in</del> April</title>
If the deletion has obscured the text such that it makes the
text difficult (but not impossible) to transcribe, nest the
unclear tag within the
del; as above, add an editorial
note if warrants further explanation or clarification is needed
(note, however, that the note is
beside the del element):
<title>While I pondered weak and <del><unclear>wary</unclear></del><note type="editorial">Possibly <mentioned>weary</mentioned>.</note></title>
If the text is rendered completely illegible, then use a
gap element with an explanatory
desc within the
del:
<title>While I pondered weak and <del><gap><desc>Illegible</desc></gap></del></title>
Substitutions
When an addition and deletion are related (i.e. the additional
text should take the place of the deleted text), then we can
encode that relationship by wrapping the
add and
del with the substitution element
subst. For example:
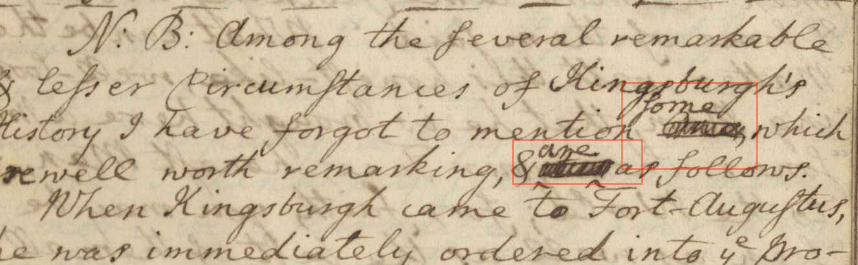
The substitions are highlighted above; in each case, there is a
deletion (with illegible content) and an addition above. In the
first example, we would encode the additional "some"
using the
addelement:
<add place="above">some</add>
<del><gap reason="deleted" quantity="1" unit="word"/></del>
To signal that these are a related substitution, we wrap the
addand the
delin a subst. So putting this all together:
<subst><add place="above">some</add><del><gap reason="deleted" quantity="1" unit="word"/></del></subst>
Unclear Text
Tag text that you are unable to transcribe text that is
partially obscured for some reason (illegible writing, scan is
missing or incompletel, external damage like ink smudges, etc)
using the unclear element:
<unclear>MacDonald</unclear>
If you'd like to expand on what is unclear, or possible other
readings, then add a note beside the
unclear using the
note element with
type=editorial
<unclear>MacDonald</unclear> <note type="editorial">Quite likely MacDonald, but could also be McDonald.</note>
If you are unable to transcribe the text at all or the text has
been removed completely (i.e. the page is burnt; the text is cut
off in the facsimile), use the gap
element with an explanatory
desc:
<gap><desc>First six words illegible due to scan.</desc></gap>
Elisions and Omissions
Text that has been purposefully omitted/elided by Forbes (e.g.
for political or social reasons) should be tagged using the
ellipsis element in combination with
a metamark and, if the omitted text
is known, a supplied. Consider the
following line from "Copy of a Letter to Captain Malcolm
MacLeod of Castle in Raaza" (v02.0323.01):
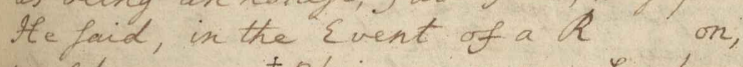
First, the gap between the "R" and "on" would
be marked as an omission using the
ellipsis element like so:
He said, in the Event of a R<ellipsis><!-- ... --></ellipsis>on,
This tells us that there is text that has been elided; to encode
the space, we use a metamark with a
child space element within the
ellipsis:
He said, in the Event of a R<ellipsis><metamark><space/></metamark></ellipsis>on,
Note that the metamark element
allows you to use either a space
element or text content (but not
both); if, for instance, the elision was signaled using em-dashes
(i.e. "Mr. F———"), then you would put the "———"
as the text value of the
metamark:
I went to the store with Mr. F<ellipsis><metamark>———</metamark></ellipsis>
To add the supplied text, place a
supplied after the
metamark like so. Make sure to use a
resp that points to your team ID to credit
yourself; if you are uncertain about your interpretation, you can
use a cert (as described above) with a value
of "low":
He said, in the Event of a R<ellipsis><metamark><space/></metamark><supplied resp="team:JT1" cert="low">estoration</supplied></ellipsis>
Elisions: Multiple Choices (Prince vs Pretender)
In cases of an initial P with a set of spaces (which can be
either Prince or Pretender), place a
choice within the
supplied with a
seg for each "rince" and
"retender" like so:
If The P<ellipsis>
<metamark><space/></metamark>
<choice>
<seg>rince</seg>
<seg>retender</seg>
</choice>
</ellipsis> returns...
Foreign Language
To tag that something is in a foreign language, use the
xml:lang attribute with an ISO language tag
value for that language:
| de | German |
| en | English |
| es | Spanish |
| fr | French |
| ga | Irish |
| gd | Scottish Gaelic |
| ghc | Hiberno-Scottish Gaelic |
| gr | Greek |
| it | Italian |
| la | Latin |
| sco | Scots |
How and where you attach that xml:lang
depends on whether the segment of foreign language is entirely
contained by a single element. For instance, if an entire
title in an
item is in French, then you can place
the xml:lang directly on the
item:
<item><title xml:lang="fr">Le petit chien</title></item>
If the foreign language appears has no logical wrapper (i.e. a
single foreign phrase in a sentence or a foreign word), then use the
foreign element:
<item><title>This example was created <foreign xml:lang="la">ex nihilo</foreign></title></item>
Multiple Hands
Annotations in different hands—i.e. additions written in a
different medium by another scribe—can be encoded using the
hand attribute in concert with the
handNotes element in the
teiHeader.
Hands are not centralized, so each distinct hand encountered in a
file needs to be encoded in the
teiHeader. Specifically, the
handNotes and
handNote element should appear in the
profileDesc, below the
limItem element:
<profileDesc>
<limItem>
<!-- Lots of metadata here... -->
</limItem>
<!-- Add a handNotes and handNote element here -->
<handNotes>
<handNote/>
</handNotes>
</profileDesc>
Encode each distinct hand in the document using the
handNote element, which must contain
an xml:id and a
medium:
<handNotes>
<handNote xml:id="hand_pencil" medium="pencil">Unknown hand in pencil</handNote>
</handNotes>
If you know the scribe, use the scribeRef
attribute to denote to whom the hand belongs:
<handNote xml:id="hand_crayon" medium="crayon" scribeRef="pers:BLOGJ1">Hand in crayon, likely J. Bloggs.</handNote>
<!-- In the teiHeader -->
<teiHeader>
<!-- [...] -->
<profileDesc>
<limItem>
<!-- [...] -->
</limItem>
<handNotes>
<handNote xml:id="hand_pencil" medium="pencil">Unknown hand in pencil</handNote>
<handNote xml:id="hand_crayon" medium="crayon" scribeRef="pers:BLOGJ1">Hand in crayon, likely J. Bloggs.</handNote>
</handNotes>
</profileDesc>
<!-- [...] -->
</teiHeader>
<text>
<body>
<!-- [...] -->
<add hand="#hand_pencil">Bogue</add>
<!-- [...] -->
<note type="lim" anchored="false" hand="#hand_crayon">
<p>[...]</p>
</note>
</body>
</text>