Transcription Encoding Workflow
We use a multi-stage workflow for the transcriptions in order to
allow for ease of collaboration during the transcription stage. All of
the transcriptions are in the Google Drive folder; depending on the
individual transcriber's preference, this transcription may have been
automatically generated from Transkribus or has been transcribed by
hand.
Once the transcription has been finished and proofed according to
the guidelines in the Google Drive, the next step is to encode the
transcription in TEI. We have an automated process for creating a
semi-valid TEI document from the Google Doc transcription. Since
Google Doc is a presentation format, the transformation from the
Google Doc to TEI will be necessarily imperfect and will require
significant manual editing in order to ensure that the structure,
semantics, and presentation of the text are encoded properly.
Step 0: Update your repository
Before encoding your transcription, make sure you have your
GitHub and oXygen environments properly set up (see
Getting Started) and that you
have update your local version of the repository (see
Workflow).
Step 1: Check Google Drive Transcription
The automated conversion process makes a number of assumptions
about the format of the Transcription Roster and the Google Doc; any
divergence from these assumptions will quite likely cause the
transformation to fail, so it is best to ensure the following before
proceeding to run the conversion:
The transcription roster MUST contain the IDs of the assigned
transcriber, the actual transcriber, and the proofer where the
ID is usually the person's initials and a 1 (i.e. JT1). If there
are multiple people for a given role, separate with a slash
(i.e. JT1/LD1).
Ensure that these cells DO NOT contain any spaces
The document ID in the first cell MUST match the name of the
document in Google Drive, which MUST match the name of the
document's ID (i.e. v01.0001.01).
Transcriptions MUST NOT contain any Track Changes (insert,
remove, format, etc). Ensure that all track changes are resolved
before converting (NB: comments and notes are OK as these are
converted to XML comments
(!-- comment --)
Once you have confirmed the above, add your ID to the ENCODER
column. This is important as we want to avoid multiple people
encoding an item.
Step 2: Convert the Transcription
Open the Google Doc transcription and copy the document's
URL
Open oXygen (and confirm you are in the lim-data project--it
should say
lim-data.xprin the corner
Scroll to the bottom of the project pane, find the file named
convertTranscription.html, and double-click it to open it
Then press the red "Play" button (a white circle
with a red triangle)
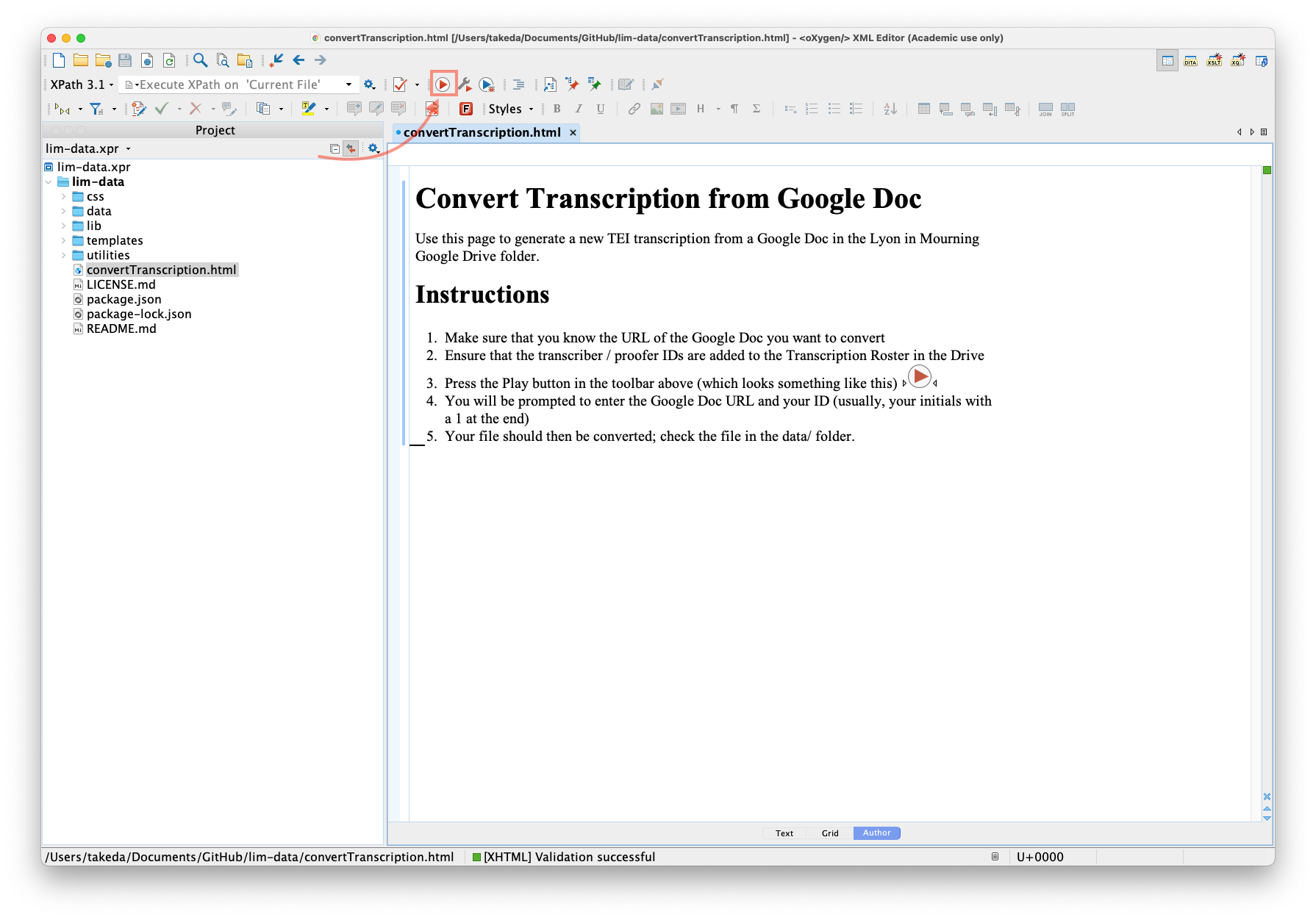
The first is your encoder ID. Enter your id (i.e. LD1) and
press OK
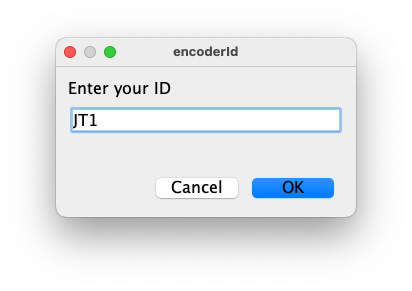
The second is the Google Doc URL. Paste in the Google Doc's
URL and press OK
A pane should appear at the bottom of your oXygen application
with a bunch of messages that scroll past as the conversion process
proceeds. This will take about a minute or so.
Once the conversion is finished (and if it did not encounter any
errors), then the document should automatically open in a new tab in
oXygen and the information at the bottom should say "BUILD
SUCCESSFUL"
If all was successful, you can close the results pane:
If the conversion fails, then a secondary tab will appear at the
bottom and will say something dramatic and unhelpful like
"FATAL ERROR."
If you see this, then there are a few steps you can take to try
and debug. Often, these errors are caused by some inconsistency in
the Transcription Roster, so double check that everything is
formatted as described above.
If the Roster looks OK, then check the "ANT
[convertGoogleDoc]" tab. There will be a lot of superfluous
information in that window, but try scrolling up a few lines and
seeing if you can find a line that begins with the words
"ERROR." These are customized error messages for this
project, which attempt to explain what caused the error. For
instance, in this example, the document had already been
transcribed:
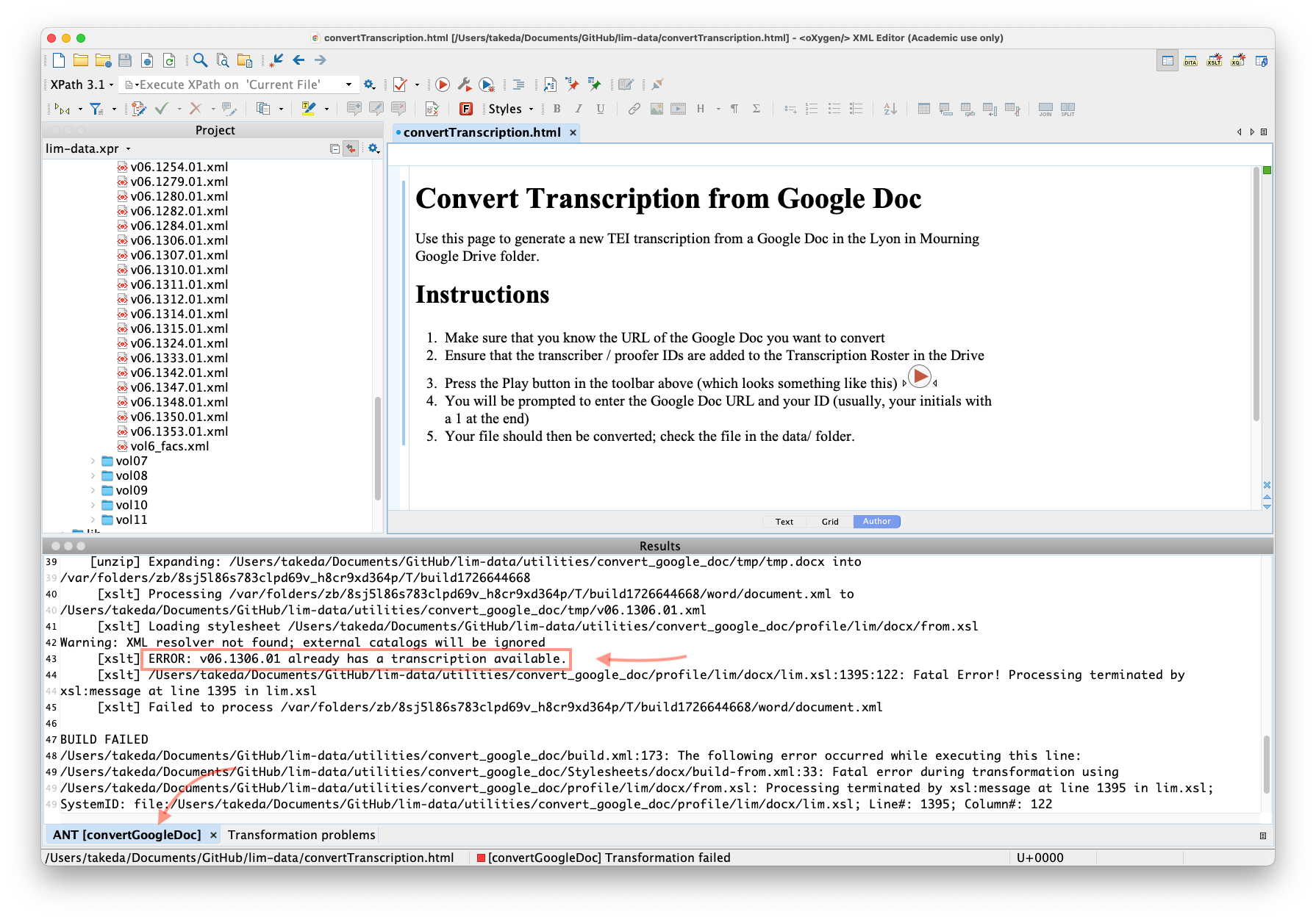
If you can't find a line like that or if it's not clear how to
resolve the issue, then the best course of action is to get in touch
with the LiM team using the RAs email list, which includes the DHIL
developer. It may be the case that another person has encountered
the same issue and knows how to fix it or there is something broken
with the conversion script. Please include the output of the ANT
[convertGoogleDoc] tab at the bottom of your message (it will be a
lot of text) since this will help with debugging the issue.
Step 3: Encoding the Transcription
The automatically generated transcription will almost certainly
be riddled with validation errors. These are expected and wanted:
the conversion tries to make some educated guesses about formatting,
etc, but will usually produce generic or intentionally invalid TEI
in order to flag places where human intervention is required.
The overall goal of this first pass of encoding is to make sure
the document is valid and accurately represents the source material.
While each document will have different requirements in terms of
encoding, there are some common errors that appear within
documents.
TODO: Add table of errors with solutions